In this day and age, social media platforms like twitter, facebook, instagram and more have troves of data waiting to be analyzed. In this project, I used twitter data. There is data in many forms that can be analyzed such as what users are tweeting from a specific country, what is the most common device being tweeted from and what are the current trends to name a few. I decided to make a simple application which displays the top ten hashtags for that day. To do this, I had to sign up on twitter to get the access tokens and consumer secrets. Twitter is currently still rolling out their v2.0 I decided to use v1.1 for my application.
The results refresh every 6 hours. Currently, have removed the dashboard from the site due to AWS free tier limits for this month.
Objectives
- Devise a method to filter messages based on "#"
- Create a pipeline to set up streaming between ec2 -> s3 -> elasticbeanstalk.
- Produce a real time dashboard which shows what is trending.
Libraries
Some of the tools required to make this project work:- Tweepy - Twitter streaming API which allows for tweet manipulation, which location to get the tweets from and more.
- Pyspark - A python version of Apache Spark that allows for handling of streaming data and performing analytics.
- Hadoop - Hadoop is another big data tool that can be used for analytics or for storing data.
- Winutils - Contains hadoop libraries to run effectively on windows.
- Chart.js - Minimalistic javascript charting application to plot nice charts with minimal code.
- Flask - Allows the development of a web application which can be accessed publicly.
- AWS CLI - Helps to communicate with AWS products such as s3, ec2, elasticbeanstalk and more.
- Socket - Utilized to easily connect two nodes to communicate.
- Cron - A linux / UNIX tool used for scheduling jobs. Files such as crontab contains instructions to for cron to execute.
Method
Tweepy streamlistener class was used to set up the streaming process. There were some additional commands added to get the extended tweet text and filter based on language which were added. A local socket was created to start the streaming on the EC2 instance. I decided to use spark streaming rather than structured streaming since we are not building an ideal application and due to AWS free tier restrictions. Furthermore, spark sets up a DStream using sockettextstream to fetch the tweepy streaming data for further processing. In spark, we split the data based on lines and filter with respect to number of hashtags. This is done using the rdd and sql_context. The processed data is then sent as a .csv to be stored in s3 for the specific day and streamed to the flask instance running on elastic beanstalk. Finally, cron is used to automate script running every 6 hours, cleaning up residual checkpoints made by spark (if any) and moving .csv files to s3.
Ideally, we can use kafka or amazon kinesis to help facilitate streaming the data, spark structured streaming for processing on multiple clusters and storing the data in one of Amazons databases.
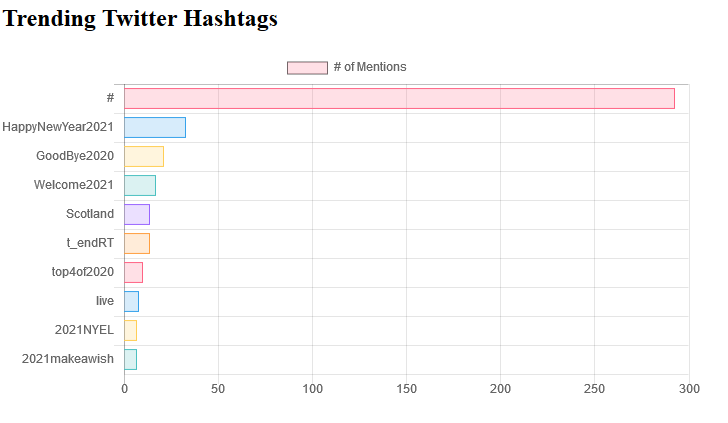
Block Diagram & Dashboard
In order to not show a blank dashboard, it shows the most recent hashtags from the .csv file stored in s3 till it gets updated after 6 hours. The # represents the number of tweets that were unique but, did not repeat therefore, were not shown in the trending hashtags graph.